Although beans are fun to design and even more fun to use, there often comes a point when it is necessary to store a bean away for later use. The process of storing a bean in a nonvolatile location for later use is known as persistence. Persistence plays an important role in JavaBeans because it gives application developers a way to save the changes they make to beans that comprise an application. Because beans see a great deal of use as application building blocks, it is imperative that the JavaBeans API provide some means of persistently storing a bean's internal state. In addition to being important in terms of builder tools, persistence enables data-oriented beans to store themselves for later retrieval.
This chapter looks at persistence and how it impacts JavaBeans. You learn about the specific mechanism used by JavaBeans to carry out the persistent storage of a bean's state. More specifically, you find out about serialization and how it is used to provide an automated approach to persistence. You also learn about an approach to persistence where bean developers have the freedom to control all the details of how a bean is stored. These two approaches to persistence parallel the two approaches to introspection about which you learned in Chapter 5, "Introspection: Getting to Know a Bean," where one is automatic while the other provides more freedom at the expense of some effort on the part of bean developers. You probably will be surprised to find out that the approach JavaBeans takes in handling persistence has more to do with the core Java API than with the JavaBeans API.
In this chapter, you learn about the following:
Persistence is the mechanism by which beans are stored away in a nonvolatile place for later use. This statement, as straightforward as it is, might not give you the full picture as to what persistence means to JavaBeans. When you think about the concept of persistence, you have to consider the issue of a bean's life cycle. In other words, in the absence of persistence, consider what the lifetime of a bean consists of. To start things off, a bean first is created, probably within the context of some application or application builder tool. Then, some properties are probably manipulated and some public methods called on the bean. After seeing some degree of use, the bean will eventually no longer be needed and will be destroyed (removed from memory), never to be seen or heard from again. Figure 7.1 illustrates the life cycle of a typical bean.
Figure
7.1. The life cycle of a bean.
Don't worry, I'm not trying to tug at your heart strings and get you feeling sorry
for helpless little beans that have met their demise. What I'm trying to do is establish
that without persistence, a bean's life cycle is limited to whatever happens in the
context of a particular session of an application. When an application ends, all
the beans that have been created alongside it are automatically destroyed. You might
be thinking that this is no big deal, considering the fact that beans are just little
objects and can easily be re-created. But remember that a significant part of using
beans is being able to customize them for use in different situations. And what good
are customized beans if the customizations are lost after you close an application?
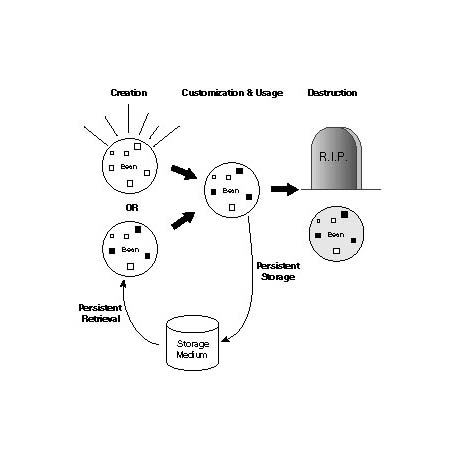
Persistence puts a twist on the life cycle of a bean by providing a means to keep
up with the state of a bean and restore it later. Check out Figure 7.2, which shows
how persistence impacts the life cycle of a bean.
Notice in the figure how the bean is not required to always be created anew. Through persistent storage and retrieval, it is possible to load a bean to the state it was in during the last session of its use. Hopefully, you are starting to get an idea about how this ability to load and use a customized bean is of great importance to JavaBeans. The issue I'm leading up to is that of application builder tools. Think about the role beans play in application builder tools: Each bean is visually laid out and then edited to fit the application being developed. When you are finished working in the builder tool, you want the customized beans to be stored somehow so they will keep the same values you set. Without persistence, you would always have to start over each time you ran the tool. In fact, there would be no point in using beans as application building blocks because they would have no way to maintain their customized state.
Figure
7.2. The life cycle of a bean with persistence.
Even though application builder tools are a good example of where bean persistence
is important, there are other areas as well. Consider situations in which beans serve
as data objects that represent some kind of important information. For example, you
could develop a custom data bean to keep track of addresses in an address book application.
The bean's role in the address book would be to provide a way to edit and maintain
information about addresses for all your friends. Well, what happens after you start
using your address book and you enter a bunch of addresses? Without persistence,
not much. As soon as you closed the application all your data would go away. With
persistence, you can easily store the addresses for future use, which is pretty much
the whole point of entering them to begin with. Without persistence, your address
book application is the equivalent of a physical paper address book where you replace
the contents with clean paper every time you go to use it. Not very useful!
The topic I've been not so carefully dancing around is that persistence is a very important facility for JavaBeans because it provides a means of preserving the state of beans for future use. I might sound like I'm repeating myself with this definition of persistence, but it is imperative that you understand the role persistence plays in JavaBeans. It certainly sounds like a simple concept--and in fact it is--but the simplest of concepts can get messy when it comes to making them a reality. Fortunately, JavaBeans goes with a very simple and straightforward approach to persistence, which you learn about throughout the rest of this chapter.
When you've concluded that persistence is important to JavaBeans, the next step is to determine exactly what information about a bean is worthy of being persistently stored. Like all Java objects, beans consist of data and methods that act on the data. The persistent aspects of a bean are usually some subset of the bean's data. Ultimately, the determination of what part of a bean's data needs to be persistent is up to bean developers. The simple conceptual way to look at the problem is to remember that the whole point of persistence is to enable beans to be restored to the exact same state they were in when they were last used.
Your first impulse might be to say that all of a bean's data should be stored away for persistent resurrection. However, there are a couple of thorny issues related to this brute force approach. First of all, it's not unusual for a bean to use member variables to keep track of temporary information. For example, a bean might use a member variable to keep up with whether the mouse button is down for some type of dragging operation. Clearly, this isn't something that should be stored away persistently because it is impossible to keep the value synchronized with the mouse's actual state. Besides, the state of the mouse can easily be determined when a bean is first created or loaded. Persistent state information should typically only include things that can't be assessed from the runtime environment.
A more important and much trickier issue relating to the type of information that should be persistently stored is references to other beans. It is perfectly acceptable for a bean to maintain member variables that are references to other beans. For example, container beans usually manage references to all the beans contained within them. The problem is that it isn't possible to store and retrieve references to beans via persistence because references are actually pointers to memory, which are very volatile. In other words, it is highly unlikely that a restored memory pointer will ever point to anything meaningful because memory is constantly changing.
The question is, what happens to bean references when it comes to persistence? I mean, aren't references to other beans just as important in the restoration of a bean's state as other member variables? Absolutely! But because JavaBeans can't address the reference problem through persistence, it pushes the responsibility on the application or application builder tool where beans are being used. Therefore, if you customize and connect a bunch of beans together using a builder tool and you save everything, the beans are stored via JavaBeans persistence but their relationships to each other are stored through some builder tool-specific mechanism.
OK, so you understand that most of the data for a bean should be persistently stored, excluding temporary information and references to other beans. The next issue to tackle is how JavaBeans itself determines what information about a bean to persistently store. Although this might at first seem like a fairly difficult challenge based on the discussion thus far, it turns out to be quite simple. The approach JavaBeans takes is to assume that all member variables are to be persistently stored away. There are no complicated rules or tricky algorithms for attempting to assess the usage of member variables, except for one minor exception.
Java supports the transient keyword, which identifies a member variable as not being part of an object's persistent state. JavaBeans also uses this variable for the same purpose. Therefore, if you are developing a bean and you have several member variables that reference other beans, you simply identify them as transient and all is well. Here is an example of a bean with a transient member variable:
public class Ratchet {
private int length, weight;
private transient ToolBox box;
public Ratchet(int l, ToolBox b) {
length = l;
box = b;
}
// Methods...
}
In this example, the Ratchet class has a transient member variable called box that is of type ToolBox. This member variable is used to hold a reference to a ToolBox object that is passed in the Ratchet class's constructor. When it comes time to persistently store a Ratchet object, only the length and weight member variables are stored; the box member variable is left for the parent application to worry about.
Throughout the discussion of persistence thus far, I've left out one crucial detail: where beans are stored. It certainly is important to understand the "how" and "what" behind persistence, but at some point you have to take into consideration the "where." You've probably been assuming that I've been talking about storing beans in files, but that's not necessarily true. Indeed, the primary approach used in storing persistent beans is files, but this is not the only approach available. It is also possible to store beans in databases.
Admittedly, this route is much less common than simply storing beans in files, but it is still worth mentioning because it shows the extensibility of JavaBeans persistence. If you don't quite understand the difference between storing a bean in a file as opposed to a database, think about the differences between a raw binary file and a database. Binary files are just a big long series of bytes, where databases are well-defined data structures usually consisting of tables with rows and columns. Therefore, when a bean gets stored in a file it goes in as a series of bytes. On the other hand, when a bean gets stored in a database, it must somehow be mapped into the structure of the database. For example, each member variable being stored might correspond to a column in the database. In either case, the process of reading or writing an object to a stream of data is called serialization.
New Term: Serialization is the process of reading or writing an object to a stream of data.
It is worth noting that JavaBeans defaults to storing beans using automatic serialization, which means that they are stored in files. The database approach to bean persistence involves considerable effort on the part of bean developers.
A particularly important goal for the JavaBeans architects was to somehow make persistence something that bean developers wouldn't have to worry about if they didn't want to. This is a common theme throughout the design of JavaBeans that I hope you are beginning to see. To make bean development as easy as possible, the JavaBeans architects really tried hard to make many of the standard facilities as automatic as possible, including persistence. However, the folks at JavaSoft also understand the importance of giving developers the freedom to chart their own course if they so desire. Therefore, the persistence facilities in JavaBeans allow for highly customized approaches to the storage of a bean's state as well. Database storage is an example of a customized approach to bean storage.
The customized approach to bean persistence is also referred to as an externalization mechanism. Support for this approach is provided so that bean developers can carefully control the way in which objects are persistently stored and retrieved. Developers who aren't concerned with this type of control are free to rely on the default persistence mechanism provided by JavaBeans. Otherwise, developers are responsible for deciding exactly how a bean is to be represented and stored for later use, which often can be a complex task.
New Term: An externalization mechanism is a means of storing and retrieving an object through some type of custom, externally defined format.
Persistence in JavaBeans is tightly linked to a feature of the core Java API:
object serialization. Serialization is the process of reading or writing an object
to
a stream of data. The Java object serialization facilities define a consistent
format for reading and writing Java objects to a stream of bytes suitable for storage
in a file. This serialization support provides a complete solution for storing and
retrieving Java objects to nonvolatile locations, such as files. One of the ways
in which JavaBeans uses serialization is in its automatic approach to persistence,
which involves storing and retrieving a bean based on its properties.
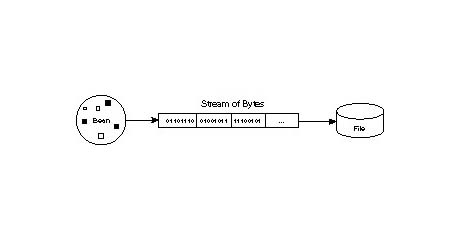
The key to storing and retrieving an object in this manner is representing the state of the object in a serialized form sufficient to reconstruct the object. In other words, the format used to store an object must sufficiently describe the object so it can be later reconstructed to the same state. From the perspective of JavaBeans, it isn't terribly important exactly how a bean is resolved into bytes, as long as it can be completely restored. Figure 7.3 shows the process of a bean being serially stored to a file as a series of bytes.
Figure
7.3. A bean being serialized to a file as
a stream of bytes.
You can see in the figure that the main premise surrounding bean serialization is
the translation of a bean into a series of bytes. Because this mechanism is already
handled by the core Java API, there isn't really any additional overhead required
by JavaBeans to support serialization. This is a result of the fact that beans are
ultimately a type of Java object, which explains why standard Java serialization
is sufficient for storing and retrieving beans. JavaBeans relies on standard Java
serialization by using it as an automatic approach to bean persistence.
The serialization functionality provided by the standard Java API has the following qualities, which help make it an ideal persistence solution for JavaBeans:
At this point, you might be starting to realize that in terms of JavaBeans, persistence and serialization mean practically the same thing. This is because JavaBeans persistence is implemented entirely through the serialization facilities provided by the core Java API. Although this might seem like the JavaBeans architects were avoiding some work, the truth is that using the standard Java serialization mechanism helps JavaBeans maintain more consistency with Java itself. The end result is that developers who understand serialization in terms of Java will also be able to work with serialization in JavaBeans without having to learn anything new. This is a good example of code reuse and how important it is to Java and related technologies such as JavaBeans.
One particularly thorny issue relating to persistence and serialization is versioning, which involves the evolution of object functionality. A big problem arises when an object is stored under one version and then restored under a different version. Because different versions of an object will often have different state information, the issue of versioning is a tricky one. Ultimately, the problem is in determining how to handle compatibility between different versions of an object. Versioning raises some interesting questions about object identity, including what constitutes a backwardly compatible change to an object--a compatible change being a change that does not affect the contract between the object and its parent application or application builder tool.
New Term: Versioning refers to the inevitable tendency for an object to evolve over time and gain new functionality.
To deal with versioning, the serialization facilities in Java must somehow enforce a set of rules ensuring that objects maintain compatibility across different versions. These rules dictate the evolution of objects by restricting the kinds of changes that can be made. More specifically, developers are restricted to adding only new member variables and interfaces, as opposed to being able to modify existing ones. So, if you have an object with a method called calcSum() that returns a float and you want to change it to return an int, you must add a new method instead of changing the original version. Your class would contain both of the following methods:
public float calcSum(); // old version public int calcSum(); // new version
This might seem like an annoyance, but it guarantees that the new version will work with code that is based on the old version. If you had simply replaced the old method with the new one, all code reliant on the float version would no longer work because the int version would result in a casting problem. The point of this example is that the trick to handling versioning is to maintain consistent interfaces across all versions of an object, which includes keeping old interfaces that might not be entirely useful in newer versions.
The serialization mechanism in the Java API addresses versioning in the following ways:
Versioning is of even greater importance to JavaBeans because beans are often distributed to a wide audience. Furthermore, the fact that beans are highly reusable means that a great deal of code is likely to be dependent on the interfaces exposed by a bean. Consequently, it is imperative that beans evolve in such a way as to maintain compatibility across different versions. Fortunately, the automatic serialization approach used by JavaBeans encourages this type of design.
Unlike other areas of JavaBeans, persistence isn't really handled by the JavaBeans API; it is implemented entirely through the serialization facilities provided by the core Java API. JavaSoft has suggested that a future release of JavaBeans might include specific support for externalized persistence, but for now there is no additional overhead in the JavaBeans API. Because the standard Java API is a little beyond the scope of this book, please feel free to refer to it on your own if you are curious about how it supports serialization. JavaSoft provides a guide to serialization as part of its standard documentation for Java, which is available separately from the JDK; just look in the JavaSoft Web site at www.javasoft.com for more information.
NOTE: Support for serialization was added in Java 1.1, so make sure you have this version of the JDK (or higher) if you are interested in learning more about serialization. You can download the latest version of the JDK directly from JavaSoft; just visit its Web site at http://www.javasoft.com.
This chapter explained persistence and how it relates to JavaBeans. You learned that persistence is the mechanism that enables beans to be stored and used later. Without persistence, a lot of the other features in JavaBeans would be ineffective. For example, what good would the builder tool customization facilities be if you couldn't save the customized beans for later use? Not much!
Even though it is very simple in concept, persistence is yet another area of JavaBeans that could have been implemented through layers of complex protocols, but instead relies on a mechanism inherent to Java itself: object serialization. Although this chapter didn't overburden you with specifics about how persistence is implemented under the hood of Java, it hopefully gave you an idea of the importance of persistence and how it applies to JavaBeans. The beauty of the persistence approach taken by JavaBeans (serialization) is that it enables you to build beans with implicit support for persistence. You don't have to perform any additional coding unless you want to customize how a bean is stored at a low level.
Your next stop on this five-chapter tour of the JavaBeans API is JavaBeans' support for application builder tools. After the next chapter, you'll have all you need to know to begin creating and using your own custom beans.
![]()
![]()
![]()
![]()
![]()
{kind=link}
{kind=link}
{kind=link}