![]()
![]()
![]()
This chapter's goal is to take a look under the hood of Index Server and provide you with greater insight about its components and workings. We hope to provide you with a better understanding of how Index Server uses catalogs, indexes, and merging to support user queries and to ensure that those queries are handled in an optimal manner. We hope this chapter provides you with a good understanding of some of the steps you can take to configure Index Server to best use your system resources while providing the best service to your users.
This chapter begins with a discussion about Index Server catalogs. You'll learn what a catalog is, how catalogs can be created, and how you might use multiple catalogs to support more advanced applications at your site. Next, you'll be introduced to indexing. You'll see how Index Server builds and uses an index, what is meant by persistent indexes, and the differences between word lists, shadow indexes, and the master index. This chapter covers merging, and discusses how Index server uses shadow-, annealing-, and master-merge operations to transport index data from word-list indexes to the master index in a manner that balances system resources with optimal query response. Finally, the chapter discusses the property cache and how Index Server uses this special index to provide optimal responses to queries about document properties.
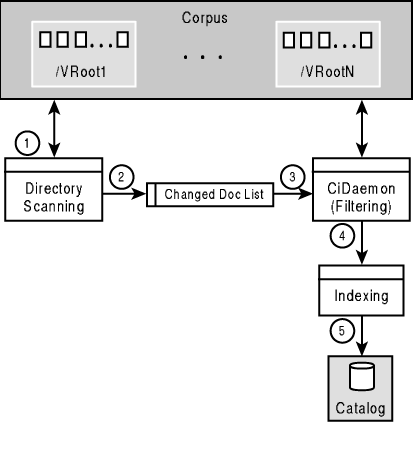
Simply put, an Index Server catalog is a directory of files that is used to maintain index and property information for virtual roots administered by IIS. The following steps outline the process by which document content and properties are added to the catalog. This process is also illustrated in Figure 10.1.
Figure 10.1. This figure illustrates the process by which a catalog is populated with index and property information for documents stored in indexed virtual roots at a site.
You can see that a catalog represents the highest level of organization performed by Index Server. The catalog is used to maintain document content and property information for documents in one or more scopes on your site. As you will see later in this chapter, this information is actually broken down and maintained in several smaller organizational units within the catalog.
When installing and setting up Index Server, a catalog directory named Catalog.wci is created. This catalog contains an index of all virtual roots that have read access. Chapter 12, "Administering Index Server," discusses the creation of virtual roots and how the scope of the catalog can be modified by enabling and disabling indexing of documents on these virtual roots.
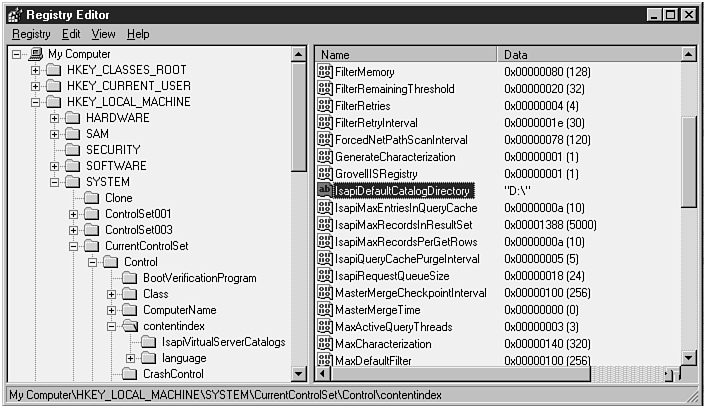
As you might recall from Chapter 3, "System Requirements," you are prompted during Index Server setup to supply the desired location for the initial catalog directory (D:\, for example). It is recommended that this location be on an NTFS drive to take advantage of NT file-system security features. During the installation process, the initial catalog location you specified is stored in the registry entry shown in the following code.
HKEY_LOCAL_MACHINE \System \CurrentControlSet \Control \ContentIndex \IsapiDefaultCatalogDirectory
The initial default catalog location on our test system is illustrated in Figure 10.2.
Figure 10.2. This highlighted registry entry shows the location of the default catalog to be used by Index Server.
Unless this location is explicitly changed in the registry, it will serve as the default catalog location for all Index Server operations (including queries and administrative operations) that do not explicitly specify which catalog to use. That means this registry value is used by all .idq files and .ida scripts (see Chapter 12) that do not explicitly set the CiCatalog parameter to the desired value. This is not a concern for sites that implement only a single catalog stored in a static location. However, in some cases, the catalog location may be changed or multiple catalogs may be used. Handling of these cases is discussed later in this chapter.
Within a catalog directory, Index Server creates and maintains a variety of permanent and semi-permanent files that are used to store information about:
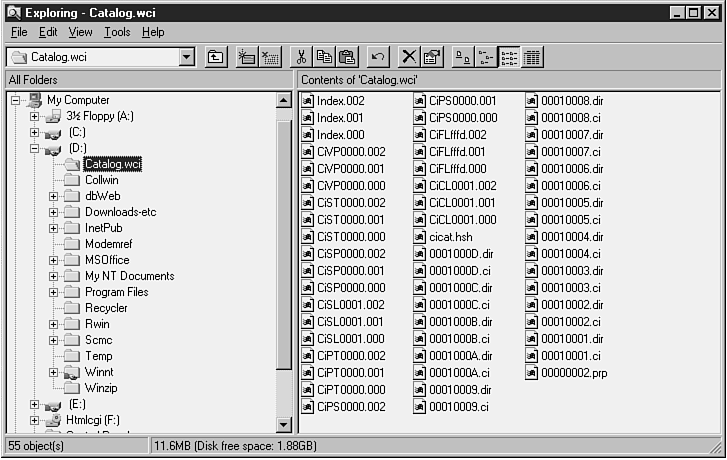
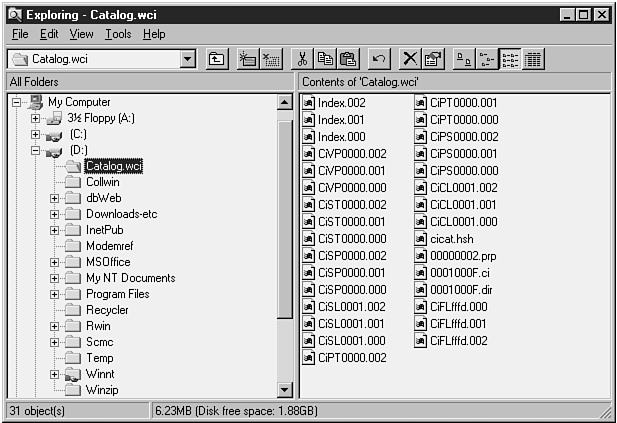
Many of these files also contain a variety of internally used data structures and mappings. Figure 10.3 illustrates the contents of the default catalog used on our test site. Note that this list represents a snapshot in time. As you'll learn later in this chapter, the number and content of some of these files fluctuates periodically during Index Server indexing and merge operations.
Figure 10.3. The variety of files stored in D:\Catalog.wci (the default Index Server catalog on our test site).
Table 10.1 lists the files Index Server creates and uses in the catalog. A brief description of each is included. Don't worry about the many references to indexes in these descriptions. Indexes are covered at length later in this chapter.
| Catalog File Name | Description of File |
| 000nnnn.prp | This file is used as an on-disk cache of frequently retrieved document properties. This cache helps optimize queries using property values. It is a large data structure comparable in size to the master index. The nnnn portion of the filename indicates the version of the cache file (00000002.prp, for example). Each modification to the property-cache schema increments this number by one. Note, however, that only a single property cache file exists at a given time. |
| 0001nnnn.ci | These files are the shadow and indexes. Several index files can exist simultaneously, and the number fluctuates periodically. Each index file is given a unique number nnnn (00010007.ci, for example). |
| 0001nnnn.dir | This file contains a directory of information that is used to quickly search a similarly named shadow index or master index (for example, 00010007.dir is the directory for the 00010007.ci index file). Several directory files can exist simultaneously, and the number fluctuates periodically. |
| cicat.hsh | This hash file provides a means for Index Server to quickly convert paths into internal identifiers used throughout the index. Only a single hash file exists at a given time. |
| CiCL0001.* | These files contain lists of files that need to be . The .* extension represents one-up file numbering,(CiCL0001.001, CiCL0001.002, and so on). |
| CiFLnnnn.* | These files contain information that is used to map documents to the most recent index for each given document. nnnn.* provides for unique file numbering, such as CiFLfffd.001. |
| CiPS0000.* | These files contain information that describes the record format of the property cache. The .* extension represents one-up file numbering (CiPS0000.001, CiPS0000.002, and so on). |
| CiPT0000.* | These files contain information that is used to map ActiveX property descriptors to internal identifiers. The .* extension represents one-up file numbering (CiPT0000.001, CiPT0000.002, and so on). |
| CiSL0001.* | These files contain lists of files that are currently in use and need to be . The .* extension represents one-up file numbering (CiSL0001.001, CiSL0001.002, and so on). |
| CiSP0000.* | These files contain lists of the physical scopes covered by this index. The .* extension represents one-up file numbering (CiSP0000.001, CiSP0000.002, and so on). |
| CiST0000.* | These files contain document-access information, which is used to map access control lists (ACLs) to internal identifiers. The .* extension represents one-up file numbering (CiST0000.001, CiST0000.002, and so on). |
| CiVP0000.* | These files contain information that is used to map between physical paths and virtual paths. The .* extension represents one-up file numbering, (CiVP0000.001, CiVP0000.002, and so on). |
| Index.* | These files contain the master lists of indexes. The .* extension represents one-up file numbering (Index.001, Index.002, and so on) . |
Index Server allows you to use more than one catalog. There are two primary reasons you might want to do this:
While using multiple catalogs provides a certain degree of flexibility, it must be done judiciously and with knowledge of the following ramifications:
To create an additional catalog on your system, perform the following steps:
After the catalog has been created, the first query against the catalog will start the process of indexing documents in the virtual roots. Indexing is covered in subsequent sections of this chapter. The virtual roots to be indexed for a given catalog can also be modified. Chapter 12 details how to enable and disable virtual-root indexing.
If you are using of IIS's virtual server-capabilities, you will probably want to associate a catalog with a specific virtual server. This is because a catalog is not associated with any specific virtual server by default, meaning that only those virtual roots without specific IP addresses will be added to the catalog.
Virtual roots without specific IP addresses are called common roots. They are indexed in all catalogs and are available for queries made to all virtual servers.
To associate a catalog with a specific virtual server, perform the following steps:
HKEY_LOCAL_MACHINE \System \CurrentControlSet \Control \ContentIndex \IsapiVirtualServerCatalogsAn entry should be made for each virtual server IP address. The name of the entry is simply the corresponding virtual server's IP address, and the value of the entry specifies the catalog location. For example, the registry entry shown in the following code would be used to associate a catalog (Catalog.wci) located at E:\Catalogs\186-134-99-77 with the virtual server having the IP address 186.134.99.77.
HKEY_LOCAL_MACHINE \System \CurrentControlSet \Control \ContentIndex \IsapiVirtualServerCatalogs \186.134.99.77=E:\Catalogs\186-134-99-77
You now have the knowledge to set up a catalog (or multiple catalogs) for a single server (or multiple virtual servers) at your installation. Using this knowledge in conjunction with the information on query forms, .idq query files, and .htx report templates (covered in Chapters 6-9), you can create customized query applications for any number of virtual servers and their associated catalogs.
Is might be necessary to change the location of a catalog or catalogs on your site. Moving or deleting a catalog is as easy as copying the Catalog.wci directory to a new location or deleting the Catalog.wci directory from your system. To perform either of these operations, follow these steps:
An index is a special data structure used to hold content and property information extracted from documents. The process by which extracted words and properties are stored in indexes is referred to as indexing. Index Server utilizes the information stored in these indexes to quickly and efficiently satisfy queries.
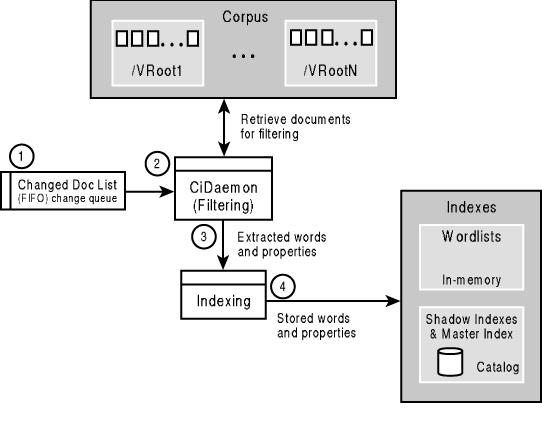
Figure 10.4 illustrates how indexes are populated. The steps involved in the process are as follows:
Figure 10.4. Words and properties extracted by filtering are stored to indexes.
Figure 10.4 indicates that three types of indexes are utilized by Index Server: word lists, shadow indexes, and a master index. These are discussed in the next section.
The catalog directory (Catalog.wci) and all indexes and other internal files within the directory are not indexed by Index Server. This is true even if the catalog directory is accessible through a virtual root enabled for indexing. This precludes the possibility of users peering into indexes that might otherwise be returned as part of a result set. Though indexes are difficult to decipher, it is possible to glean information about the contents of some files.
Word lists, shadow indexes, and the master index are all internal to Index Server, meaning that the details of these indexes are completely transparent to users. At any given time, there can exist several indexes in memory and in the catalog. However, users are aware of the existence of an index only because their queries are handled efficiently and their results are returned and presented quickly.
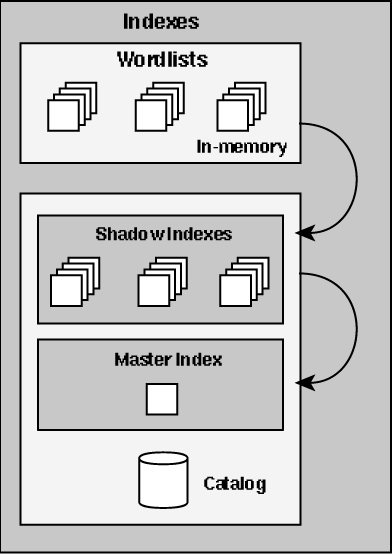
Index Server implements multiple types of indexes primarily because this type of organization allows Index Server to optimize query responsiveness and performance. The use of multiple indexes also ensures the optimal use of system resources (such as memory and disk space). As words and properties are extracted from documents, they first appear in a word list, then move to a shadow index, and eventually are stored in the master index. This process is illustrated in Figure 10.5.
Figure 10.5. This figure illustrates that words and properties extracted by filtering are first stored to word-list indexes, and eventually moved to the master index.
In the next three sections, you'll take a closer look at the types of indexes used by Index Server.
As soon as a document is filtered, the extracted data is stored in a word list. Word lists are small, temporary, non-persistent (that is, in-memory) indexes that are used to store data for a small number of filtered documents. Data written to word lists undergoes a certain degree of compression. However, because word lists are temporary structures, the amount of compression is not high.
Several word lists can exist in memory at a given time; as one fills up, a new one is created. Because word lists are in-memory objects, they can be created and populated very quickly without requiring any on-disk updates to occur at the time a document is filtered and indexed. Instead, word lists serve as a temporary staging area for index data that will eventually be propagated to on-disk shadow indexes by a process called merging. Merging is discussed in detail in a later section of this chapter.
Because word lists are in-memory structures, any information in these structures is lost if IIS/Index Server is shutdown. Therefore, any documents represented by data in a word list will need to be re-filtered when IIS/Index Server is restarted. The need for re-filtering is detected and performed automatically by Index Server.
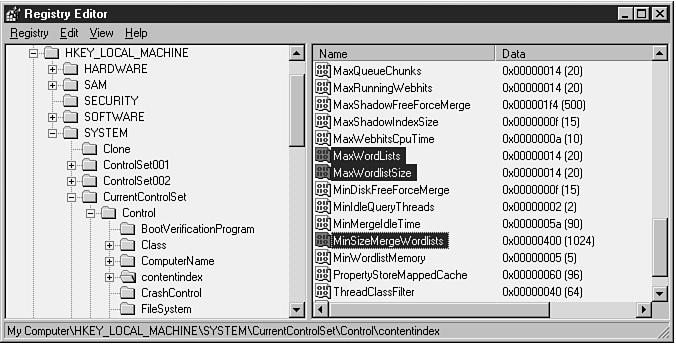
Three registry parameters control the behavior of word lists and how data in these lists is propagated to shadow indexes on disk: MaxWordLists, MaxWordlistSize and MinSizeMergeWordlists. Each of these registry parameters is stored under the registry path shown in the following code.
HKEY_LOCAL_MACHINE \System \CurrentControlSet \Control \ContentIndex
Figure 10.6 shows the values for these registry settings on our system.
Figure 10.6. These highlighted registry entries show the values for parameters controlling word-list behavior on our test system.
As you learned in the previous section, non-persistent indexes are in-memory, minimally compressed data structures that do not survive Index Server shutdowns. In contrast, persistent indexes are on-disk, highly compressed data structures that do survive server shutdowns. There are two types of persistent indexes:
Both of these indexes are stored with other internal files in the catalog directory Catalog.wci. They are further explained here:
The maximum total number of persistent indexes in a catalog is 255.
As previously stated, words and document properties extracted during document filtering are first added to word lists. From there, they propagate through shadow indexes and eventually become part of the master index.
Index Server implements this propagation using a process called merging. Merging is simply the process of consolidating the data stored in multiple source indexes into a single target index. This consolidation results in the following benefits:
Index Server performs three types of merges:
These merges are described in following sections.
Merge operations are affected by the amount of disk space available on the catalog drive. If insufficient space is available, it is possible to run out of needed disk space while a merge is occurring. If this happens during a shadow merge, merge operations are aborted (and retried when disk space is freed). If it happens during a master merge, merge operations are paused and event messages are written to the NT event log. If this occurs, do not delete any files under the catalog directory. Instead, free disk space by moving or removing other files from the drive the catalog directory is on. Index Server restarts the master merge when it detects sufficient free disk space.
A shadow merge is a process by which multiple word-list source indexes (and sometimes other shadow indexes) are combined, further compressed, and stored in a target shadow index. A shadow merge is performed to free memory resources, and makes non-persistent index data persistent by storing it on disk. Shadow merges are typically very quick operations. Index Server automatically performs shadow merges when one of the following conditions are met:
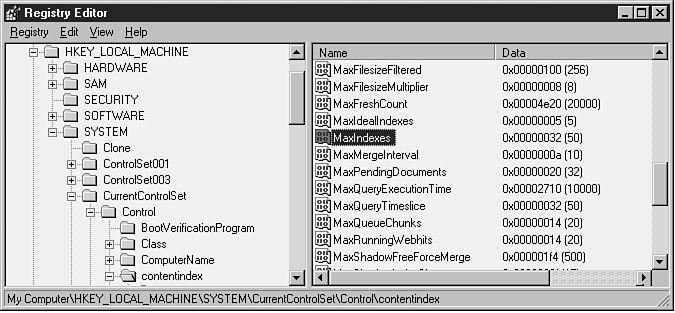
Index Server typically uses word lists as the source indexes for performing a shadow merge. However, under a certain condition, shadow indexes can also be used as source indexes. This condition is controlled by the registry parameter MaxIndexes, as shown in the following code.
HKEY_LOCAL_MACHINE \System \CurrentControlSet \Control \ContentIndex \MaxIndexes
The value of the MaxIndexes registry parameter specifies the maximum total number of persistent indexes allowed in the catalog. If exceeded, Index Server performs a shadow merge (using shadow indexes as source indexes) to bring the total number of indexes below this value. The default value is 50. Figure 10.7 shows the values for this registry setting on our system.
Figure 10.7. This highlighted registry entry shows the value on our test system for the MaxIndexes parameter, which affects shadow merge behavior.
An annealing merge is actually just a special form of a shadow merge that merges word lists and shadow indexes into a target shadow index. Annealing merges are performed when the following operational conditions are jointly satisfied:
When these conditions are met, an annealing merge is performed to bring the total count of indexes to the number specified by MaxIdealIndexes. Annealing merges reduce disk-space usage and improve query performance.
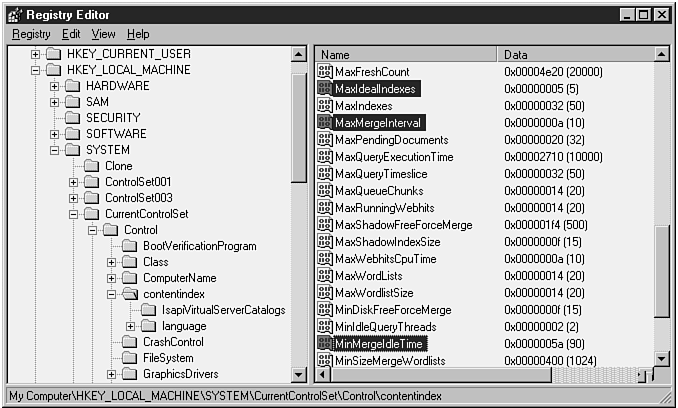
The conditions resulting in an annealing merge are affected by registry parameters MaxIdealIndexes, MaxMergeInterval, and MinMergeIdleTime, which are stored under the registry path shown in the following code.
HKEY_LOCAL_MACHINE \System \CurrentControlSet \Control \ContentIndex
MaxIdealIndexes, MaxMergeInterval and MinMergeIdleTime perform the following:
Figure 10.8 shows the values for these registry settings on our system.
Figure 10.8. These highlighted registry entries show the values for parameters affecting annealing-merge behavior on our test system.
A master merge is a process by which all shadow indexes and the current master index (if one exists) are merged to a single target master index. Master merges are very resource-intensive operations. They can consume large amounts of CPU time and disk space, and can run for quite a long time depending on the size of the source indexes being merged. After the master merge is complete, though, source indexes are deleted, index data redundancy is eliminated, and resources are freed. As a result, query resolution is typically optimized immediately following a master merge. A comparison of the files listed in Figures 10.3 and 10.9 illustrate how the source files in the catalog are reduced after a master merge is completed. A comparison shows that a master merge reduced the total number of files from 55 to 31.
Figure 10.9. This figure illustrates how the number of index files in the catalog are reduced by a master merge operation. Contrast this with the number of files shown in figure 10.3 prior to the master merge.
Index Server automatically begins a master merge when it detects certain conditions that warrant it. Index Server also provides you with the ability to manually perform the merge. Master merges are performed under any of the following conditions:
The conditions under which master merges are performed are affected by registry parameters MasterMergeTime, MaxFreshCount, MinDiskFreeForceMerge, MaxShadowFreeForceMerge, and MaxShadowIndexSize and are stored under the registry path shown in the following code.
HKEY_LOCAL_MACHINE \System \CurrentControlSet \Control \ContentIndex
The MasterMergeTime, MaxFreshCount, MinDiskFreeForceMerge, MaxShadowFreeForceMerge and MaxShadowIndexSize perform the following:
Figure 10.10 shows the values for these registry settings on our system.
Figure 10.10. The highlighted registry entries show the values for parameters affecting master merge behavior on our test system.
Index Server provides the capability to perform queries not only about document content, but also about document properties. To support these types of queries, Index Server maintains a special type of index called the property cache. The property cache is a large, on-disk data structure (comparable in size to the master index) that is used to store content index information.
The property cache is optimized to speed responses to queries on frequently used properties such as the following as well as queries on other values that Index Server uses internally.
The current version of Index Server does not support caching of custom properties. However, future versions of Index Server will provide administrators with the ability to configure the cache so that custom properties can be stored.
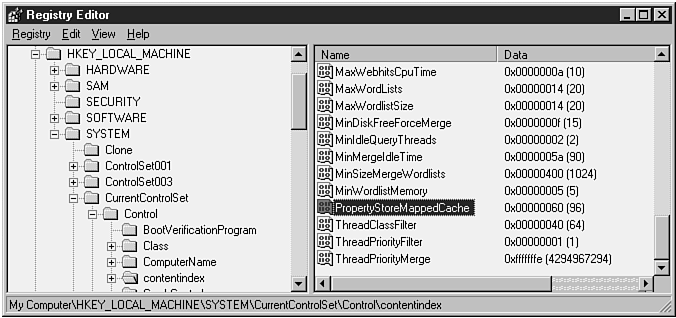
While the property cache is an on-disk data store, a large portion of the cache is always kept in memory to improve query response. The amount of the property cache maintained in memory is controlled by the PropertyStoreMappedCache registry parameter, which is shown in the following code. The value of this registry parameter specifies the maximum number of 64KB in-memory buffers to use for maintaining property cache information in memory. The default value is 16.
HKEY_LOCAL_MACHINE \System \CurrentControlSet \Control \ContentIndex \PropertyStoreMappedCache
Figure 10.11 shows the value for this registry setting on our system.
Figure 10.11. The highlighted registry entry shows the value for the PropertyStoreMappedCache parameter, which controls the amount of in-memory property-cache information on our test system.
On servers with large amounts of memory, the value of the PropertyStoreMappedCache parameter can be set to a higher value to improve performance. However, if the value is set too high when memory is inadequate, performance can actually suffer.
In this chapter, you were presented with an in-depth look at some of the behind-the-scenes components and workings of Index Server, specifically catalogs, indexes and merging. The chapter started with a discussion about what a catalog is (including the various files maintained within the catalog), and explained how multiple catalogs could be created and used to support virtual servers. Next, you were presented with an overview of what an index is and the types of indexes employed by Index Server. These included non-persistent indexes (word lists) and persistent indexes (shadow indexes and the master index). Index merging was the next topic of discussion, and you learned how Index Server maintains its index structures by propagating non-persistent indexes to the master index by performing shadow, annealing, and master merges. Finally, you looked briefly at the property cache and how it is used to optimize the performance of property queries.
![]()
![]()
![]()
![]()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}